CH-1 : A Tour of Computer Systems
preface
컴퓨터 시스템 : (어플리케이션 프로그램을 실행하기 위해 작동하는) 하드웨어 + 소프트웨어
이런 시스템의 구체적인 구현은 시간이 지남에 따라서 변하지만, 근본적인 개념은 변하지 않는다. 모든 컴퓨터 시스템은 비슷한 하드웨어와 소프트웨어 컴포넌트를 가지고 있고, 비슷한 기능을 수행한다.
이 책은 이러한 컴포넌트들이 어떻게 작동하는지, 프로그램의 정확성과 성능에 어떤 영향을 미치는지 이해함으로써 기술을 더 발전시키고자 하는 프로그래머들을 위해 쓰여졌다.
-
컴퓨터가 숫자를 표현하는 방식으로 인해 발생하는 수치오류를 피하는 방법과 같은 실무 기술을 배울 것이다.
- 최신 프로세서와 메모리 시스템의 설계를 활용하는 영리하는 트릭을 사용하여 C코드를 최적화하는 방법을 배우게 된다.
- 컴파일러가 어떻게 프로시저 호출을 구현하는지, 네트워크와 인터넷 소프트웨어를 괴롭히는 버퍼 오퍼플로우 취약점으로부터 보안 구멍을 피하기 위해 이 지식을 사용하는 방법을 배울 것이다.
- 링크 시간 동안 심각한 오류를 인식하고 피하는 방법을 배운다.
- 본인의 유닉스 셀, 동적 스토리지 할당 패키지, 웹 서버를 만드는 방법을 배운다.
- multi 프로세서 코어가 single 칩들에 통합됨에 따라 중요성이 증가하는 주제인 동시성의 약속과 위험에 대해 배울 것이다.
이번 장에서는 흔히 C 프로그램을 소개할 때 나오는 hello 프로그램의 life time을 따라가면서 핵심 개념과 용어, 실전에 사용하는 컴포넌트들을 소개한다. 다음장에서는 이런 아이디어를 확장한다.
#include <stdio.h>
int main(){
printf("hello, world\n");
return 0;
}
1.1 Information Is Bits + Context
[Fig 1.2] The ASCII text representation of hello.c

프로그래머가 만든 text file인 hello.c 프로그램은 source program(또는 source file)이라고 부른다. source 프로그램은 0과1의 값을 가진 bits의 연속이다. 합쳐진 8-bit 묶음을 byte라고 부른다. 각각의 byte는 프로그램에서 text character를 표현한다.
대부분의 컴퓨터 시스템은 ASCII 코드를 사용해서 각각의 character를 byte size의 정수값으로 나타낸다. 예를들어, 위의 [Fig 1.1]를 ASCII 코드로 나타내면 [Fig 1.2]와 같다.
hello.c 프로그램도 byte의 연속인 파일이다. 각각의 byte는 어떤 문자와 일치하는 정수값을 가진다.
예를들어, 첫번째 byte는 정수값 35로 나타내어지는데 이는 ‘#’문자와 매칭된다. 두번째 byte는 정수값 105로 나타내어지는데, 이는 ‘i’문자와 매칭된다. 그리고, 각각의 줄이 개행문자열인 ‘\n’으로 끝난다.
hello.c와 같이 ASCII문자열로만 이루어진 파일이 text files이다. 다른 나머지 파일들은 binary files이다.
hello.c 예시는 시스템의 모든 정보(디스크, 메모리에 저장된 프로그램, 메모리데 저장된 사용자 데이터, 네트워크를 통해 전송되는 데이터)는 비트들의 묶음으로 이루어졌다는 근본적인 아이디어를 보여준다.
서로 다른 data objects를 구별하는 유일한 방법은 해당 objects를 보는 맥락이다. 더 자세히 예시를 들어보자면, 같은 byte의 시퀀스라도 다른 맥락에서보면 정수, 소수, 문자열, 시스템 명령과 같이 달라질 수 있다는 말이다.
우리는 프로그래머로써, 숫자의 기계적 표현을 이해할 수 있어야한다. 왜냐하면 그 숫자는 우리가 알고있는 정수와 실수가 아니기 때문이다. 이 숫자는 예상치 못한 방식으로 작동할 수 있는 유한한 근사치이다. 이 기본 아이디어에 대해서는 2장에서 다룬다.
1.2 Programs Are Translted by Other Programs into Different Forms
hello.c 의 실행절차(소스코드 -> 목적코드)
hello.c는 high-level C program (사람이 읽고 이해하기 쉬움) -> low-level machine-language 명령어(instruction)로 변경 -> 명령어가 excutable object program로 패키지되어 binary disk file1로 저장됨
[Fig 1.3] The compliation system
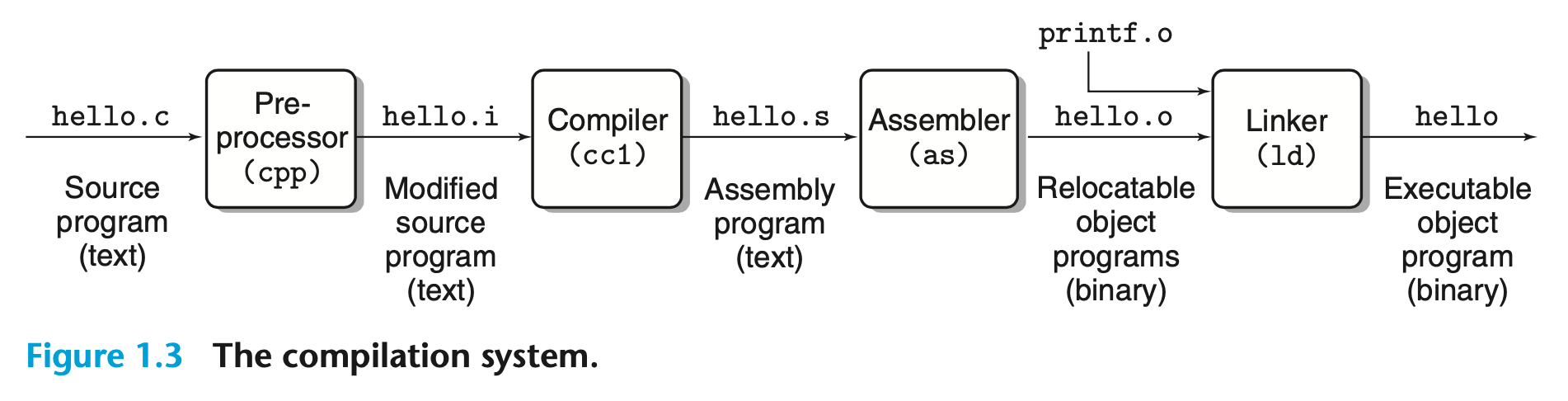
Unix 시스템에서는 source file -> object file 과정이 compiler driver를 통해 수행된다. 명령어는 다음과 같다.
linux> gcc -o hello hello.c
이 명령어의 의미는 다음과 같다.
compiler driver가 source file인 hello.c를 읽는다.- hello.c를 executable object file인 hello로 변환한다.
이 변환과정은 [Fig 1.3]이고, 4개의 연속된 과정을 수행한다. 하나하나 살펴보도록 하자.
four phase of compilation system
- Preprocessing phase
Preprocessor(cpp)는 #문자로 시작하는 지시어에 따라 기존 C프로그램을 수정한다.
예를들어, hello.c의 1번째 줄에 있는 #include<stdio.h> 명령어(command)가 preprocessor에게 시스템 헤더 파일인 stdio.h를 읽고 프로그램 텍스트에 직접 넣으라고 지시한다.2
그 결과로 .i 접미사가 붙은 다른 C프로그램이 생성된다.
- Compilation phase
compiler(cc1)는 C프로그램 text file인 hello.i를 assembly-language프로그램 text file인 hello.s 로 변환한다.
이 프로그램은 main function에 다음과 같은 정의들을 포함하고 있다.
main:
subq $8, %rsp
movl $.LCO, %edi
call puts
movl $0, %eax
addq $8, %rsp
ret
이 definition의 2~7번째 줄은 low-level machine language의 명령을 텍스트 형식으로 표현한 것이다.3
- Assembly phase
assembler(as)는 hello.s를 machine language 명령으로 변환시키고 relocatable object program으로 패키징해,object file인 hello.o에 저장한다. 이 오브젝트 파일은 main 함수의 명령어를 encode하기 위해 17byte를 포함하는 binary file이다.4
- Linking phase
hello 프로그램은 모든 C컴파일러가 제공하는 표준 C라이브러리의 일부인 printf 함수를 호출하고, printf 함수는 printf.o라고 하는 별도의 사 전 컴파일된 object file에 존재하며, 이 파일은 hello.o 프로그램과 병합되어야 한다. linker(ld)는 이 병합을 처리한다.
그 결과,hello파일은 메모리에 로드되어 시스템에 의해 실행될 준비가 된 executable object file이 된다.
1.3 It Pays to Understand How Compilation Systems Work
hello.c와 같은 간단한 프로그램들의 경우 컴파일 시스템에 의존하여 효율적이고 정확한 machine code를 생성할 수 있다. 그러나 프로그래머가 컴파일 시스템의 작동방식을 이해하는 몇가지 중요한 이유가 있다.
1. Optimizing program performance
최신 컴파일러는 일반적으로 좋은 코드를 생성하는 정교한 도구이다. 프로그래머로서 우리는 효율적인 코드를 작성하기 위해 컴파일러의 내부 동작을 알 필요가 없다.
그러나, C프로그램에서 올바른 코드를 짜는 결정을 내리기 위해서는 machine-level 코드와 컴파일러가 다른 C문을 machine code로 변환하는 방법에 대한 기본적인 이해가 필요하다.
다음과 같은 질문들이 있을 수 있다.
- switch문이 항상 if-else문 보다 효율적인가?
- 함수 호출로 발생되는 오버헤드는 얼마인가?
- while loop은 for loop 효율적인가?
- 포인터 reference가 array index 보다 효율적인가?
- loop문에
pass by reference로 전달되는 argument 대신에 local variable로 sum을 수행하면 더 빠른 이유가 무엇일까? - 산술 표현식에서 단순히 괄호를 재배열하면 함수가 더 빨리 실행 될 수 있는가?
이것에 대한 답변은 3~6장에 나와있다.
2. Understanding link-time errors
큰 소프트웨어 시스템을 만드려고 할 때, 가장 복잡한 프로그래밍 에러 중 하나는 linker의 작동과 연관되어 있다.
다음과 같은 질문들이 있을 수 있다.
- 링커가 참조를 확인할 수 없다고 하는 것은 무엇을 의미할까?
- 정적 변수와 전역 변수의 차이점은 무엇일까?
- 같은 이름을 가진 다른 C 파일에 두 개의 전역 변수를 정의하면 어떻게 될 까?
- 정적 라이브러리와 동적 라이브러리의 차이점은 무엇일까?
- 명령줄에 라이브러리를 나열하는 순서가 왜 중요할까?
- 그리고 무엇보다도, 일부 링커 관련 오류가 런타임까지 나타나지 않는 이유는 무엇일까?
이것에 대한 답변은 7장에 나와있다.
3. Avoiding security holes
많은 시간동안, buffer overflow 취약점은 네트워크와 인터넷 서버에서 security hole들의 원인이었다. 이러한 취약점이 존재하는 이유는 소수의 프로그래머들만이 신뢰할 수 없는 소스에서 허용하는 데이터의 양과 형식을 신중하게 제한해야 할 필요성을 이해하기 때문이다.
보안 프로그래밍을 배우는 첫 번째 단계는 데이터와 제어 정보가 프로그램 스택에 저장되는 방식의 결과를 이해하는 것입니다. 어셈블리 언어 연구의 일환으로 3장에서 스택 원칙과 버퍼 오버플로 취약점을 다룬다.
우리는 또한 공격의 위협을 줄이기 위해 프로그래머, 컴파일러 및 운영 체제에서 사용할 수 있는 방법에 대해 배울 것이다.
1.4 Processors Read and Interpret Instructions Store in Meomory
이 시점에서 hello.c 소스 프로그램은 컴파일 시스템에 의해 디스크에 저장된 hello라는 executable object file로 변환되었습니다. Unix 시스템에서 실행 파일을 실행하려면 shell이라고 하는 응용 프로그램에 파일 이름을 입력합니다.
linux> ./hello
hello, world
linux>
셸은 프롬프트를 출력하고 command를 입력할 때까지 기다린 다음 명령을 수행하는 command-line interperter(해석기)입니다.
command-line의 첫 번째 단어가 내장 shell 명령에 해당하지 않으면 shell은 로드하고 실행해야 하는 실행 파일의 이름이라고 가정한다.
따라서 이 경우 쉘은 hello 프로그램을 로드하고 실행한 다음 종료될 때까지 기다린다. hello 프로그램은 메시지를 화면에 출력한 다음 종료한다. 그런 다음 셸은 프롬프트를 인쇄하고 다음 입력 명령줄을 기다린다.
1.4.1 Hardware Organization of a System
[Fig 1.4] Hardware organization of typical system
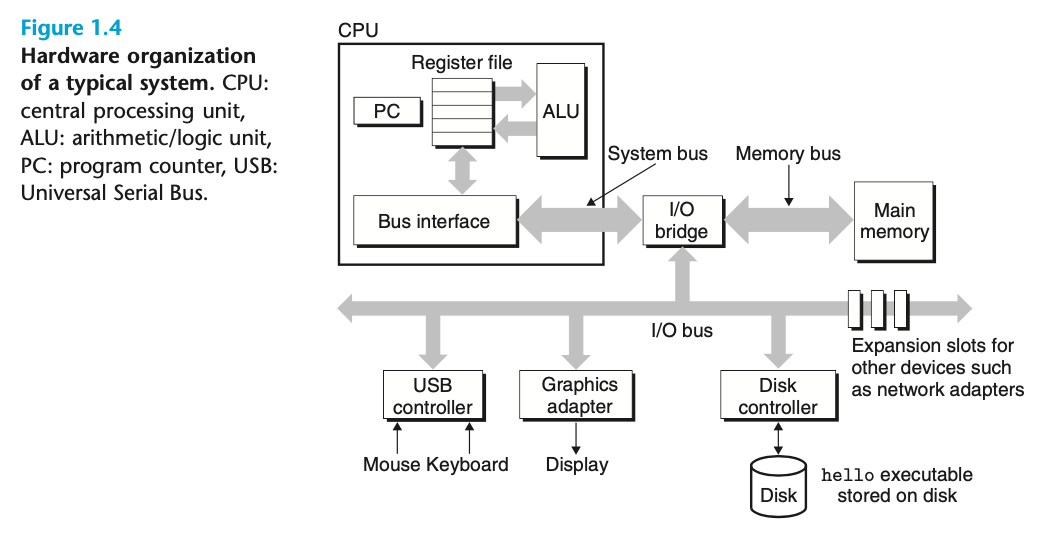
hello 프로그램을 실행할 때 어떻게 되는지 이해하려면 [Fig 1.4]에서 볼 수 있는 일반적인 시스템의 하드웨어 구성을 이해해야 한다.
위 그림은 최신 Intel 시스템 제품군을 모델로 하고 있지만 모든 시스템의 모양과 느낌은 비슷하다. 이 그림이 복잡하도고 느낄 수 있지만, 책이 진행되는 동안 단계적으로 다양한 세부 사항을 알게 될 것이다.
1. Buses
Bus : 일반적으로 word라고 하는 고정 크기의 바이트 청크를 전송하는 곳.
시스템 전체에 걸쳐 구성 요소 간에 바이트 정보를 주고받는 Bus라고 하는 전기 도관의 모음이 실행된다.
word의 바이트 수는 시스템에 따라 달라지는 기본적인 시스템 매개변수. 대부분의 기계는 4바이트(32비트) 또는 8바이트(64비트)의 word size를 가지고 있다.
2. I/O Devices
I/O Devices : 외부 세계에 대한 시스템의 연결.
예제 시스템에는 4개의 I/O 장치가 있다.
- 키보드
- 마우스
- 디스플레이
- 디스크 드라이브 - 처음에 executable hello program은 disk에 있다.
각 I/O 장치는 controller나 adapter를 통해 I/O bus에 연결된다. controller 와 adapter의 주요 차이점은 packaging이다.
Controller
controller는 장치 자체 or 시스템의 마더보드에 있는 칩셋
Adapter
adapter는 마더보드의 슬롯에 꽃는 카드
서로 다름에도 불구하고, I/O Bus 와 I/O device간에 정보를 주고받는다는 목적은 똑같다.
3. Main Memory
Main memory : processor가 프로그램을 실행하는 동안 프로그램과 프로그램이 조작하는 데이터를 모두 보유하는 임시 저장 장치.
물리적인 구성 : Dram(Dynamic Random Access Memory)칩 모음으로 구성됨.
논리적인 구성 : 0에서 시작하는 고유한 address(array index)가 있는 byte의 선형 배열로 구성.
4. Processor
CPU(control processing unit) (processor라고도 함) : 주 메모리에 저장된 명령을 해석(또는 실행)하는 엔진.
CPU의 핵심 : Program Counter(PC) 라고 하는 word-size storage device(register의 일부)
어느 시점에서든 PC는 main memory에 있는 machine-language instruction를 가르키고 있다(address 포함).
시스템에 전원이 들어오는 시점부터 전원이 차단될 때까지 processor는 PC가 가르키는 명령을 반복적으로 실행하고 다음명령을 가리키도록 PC를 업데이트한다.
processor는 Instruction Set Architecture(명령어 집합 구조, ISA)5 로 정의된 간단한 명령어 실행 모델에 따라 작동한다.
이 모델에서 명령은 엄격한 순서로 실행되며, 단일 명령을 실행하려면 일련의 단계를 수행해야 된다.
- precessor는 PC가 가르키는 memory에서 명령을 읽는다.
- 명령의 bit를 해석한다.
- PC가 다음 명령을 가리키도록 업데이트한다.(방금 실행된 명령어와 인접한 address)
이런 간단한 작업이 조금밖에 없으며, 이런 작업은 main memory, register file, arithmetic/logic unit(ALU) 중심으로 순환한다.
- register file : 각각 고유한 이름을 가진 word-size register 모음으로 구성된 작은 저장 장치.
- ALU : 새 데이터와 주소 값을 계산한다.
다음은 명령 요청 시 CPU가 수행할 수 있는 간단한 작업의 몇가지 예이다.
- Load : byte 또는 word를 main memory에서 register로 복사하여 register의 이전 내용을 덮어쓴다.
- Store : register의 byte 또는 word를 main memory에 있는 위치로 복사하여 이전 내용을 덮어쓴다.
- Operation : 두 register의 내용을 ALU에 복사하고, 두 word에 대한 산술 연산을 수행한 후 register에 결과를 저장하여 해당 register의 이전 내용을 덮어쓴다.
- Jump : 명령 자체에서 word를 추출하여 PC에 복사하여 PC의 이전 값을 덮어쓴다.
processor가 ISA의 단순한 구현인 것처럼 보이지만, 사실 현대 프로세서는 프로그램 실행 속도를 높이기 위해 훨씬 더 복잡한 메커니즘을 사용한다.
따라서 우리는 각 machine-code instruction의 효과를 설명하는 ISA와 프로세서가 실제로 구현되는 방식을 설명하는 microarchitecture6를 구별할 수 있다.
microarchitecture와 명령어 집합 구조(ISA)는 함께 컴퓨터 아키텍처의 분야를 구성하고 있다.
1.4.2 Running the hello program
[Fig 1.5] Reading the hello command from the keyboard
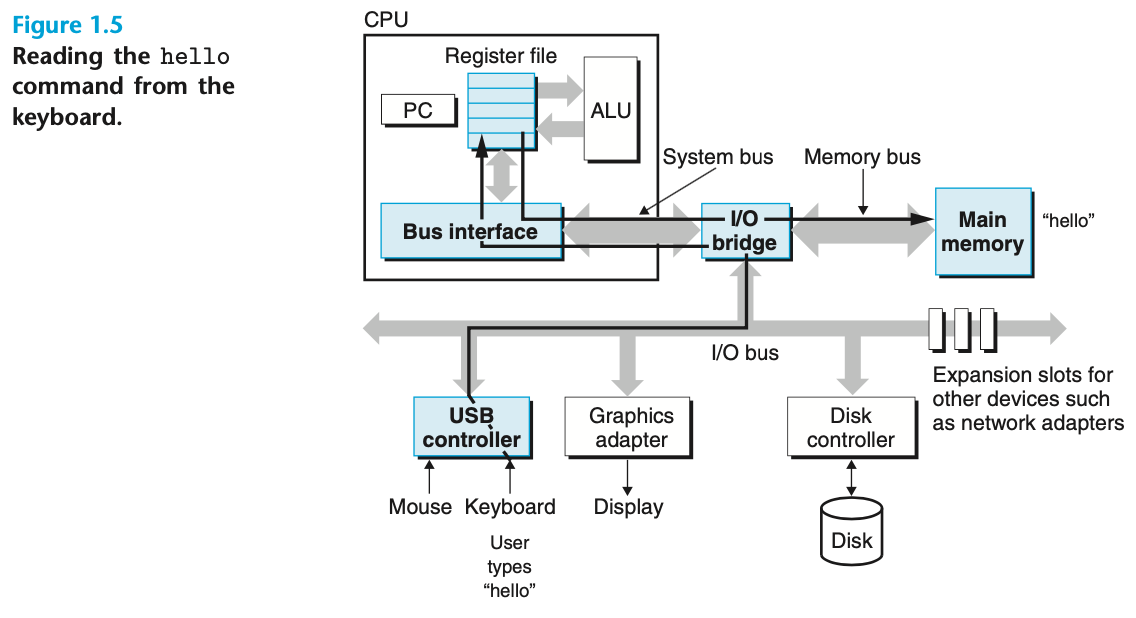
- 처음에 shell program은 instruction을 실행하면서 우리가 command를 입력하기를 기다린다.
- 키보드에 ./hello 입력.
- 각 문자를 register로 읽은 후 memory에 저장.
위의 [Fig 1.5]를 참고하면 다음과 같다.
-> keyboard
-> I/O bridge
-> Bus interface
-> Register file
-> Bus interface
-> I/O bridge
-> Main memory
와 같은 형태로 memory에 hello가 저장된다.(파일 이름 저장)
[Fig 1.6] Loading the executable from disk into main memory
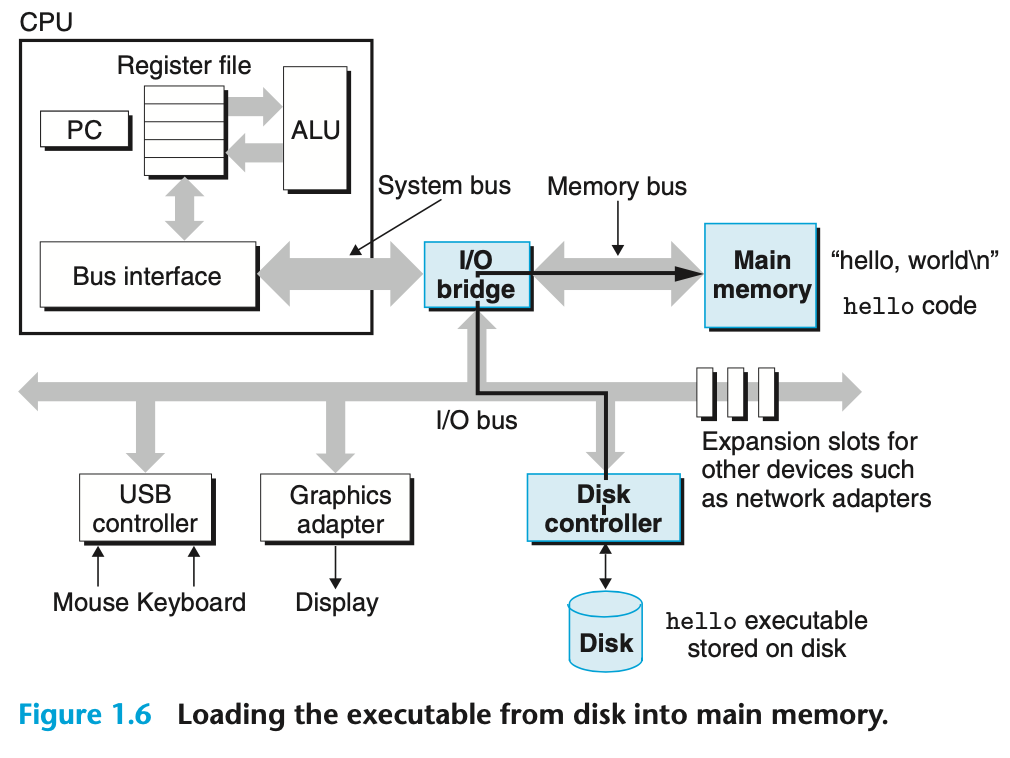
키보드에서 Enter 키를 누르면 shell은 명령 입력이 완료되었음을 알 수 있다.
- shell은 hello executable object file
코드와데이터를 disk에서 main memeory로 복사하는 일련의 instructions를 실행하여 hello executable object file을 로드한다. 데이터에는 print 될 문자열 hello, world\n가 포함된다. - direct memory access(DMA, 6장에서 설명)로 알려진 기술을 사용하여 데이터는 프로세서를 거치지 않고 디스크에서 주 메모리로 직접 이동한다.
위의 [Fig 1.6]를 참고하면 다음과 같다.
-> Disk
-> Disk Controller
-> I/O bridge
-> Main memory
와 같은 경로로 executable hello(코드 & 데이터)를 Disk -> Main memory로 이동시킨다.
[Fig 1.7] Writing the output string from memory to the display
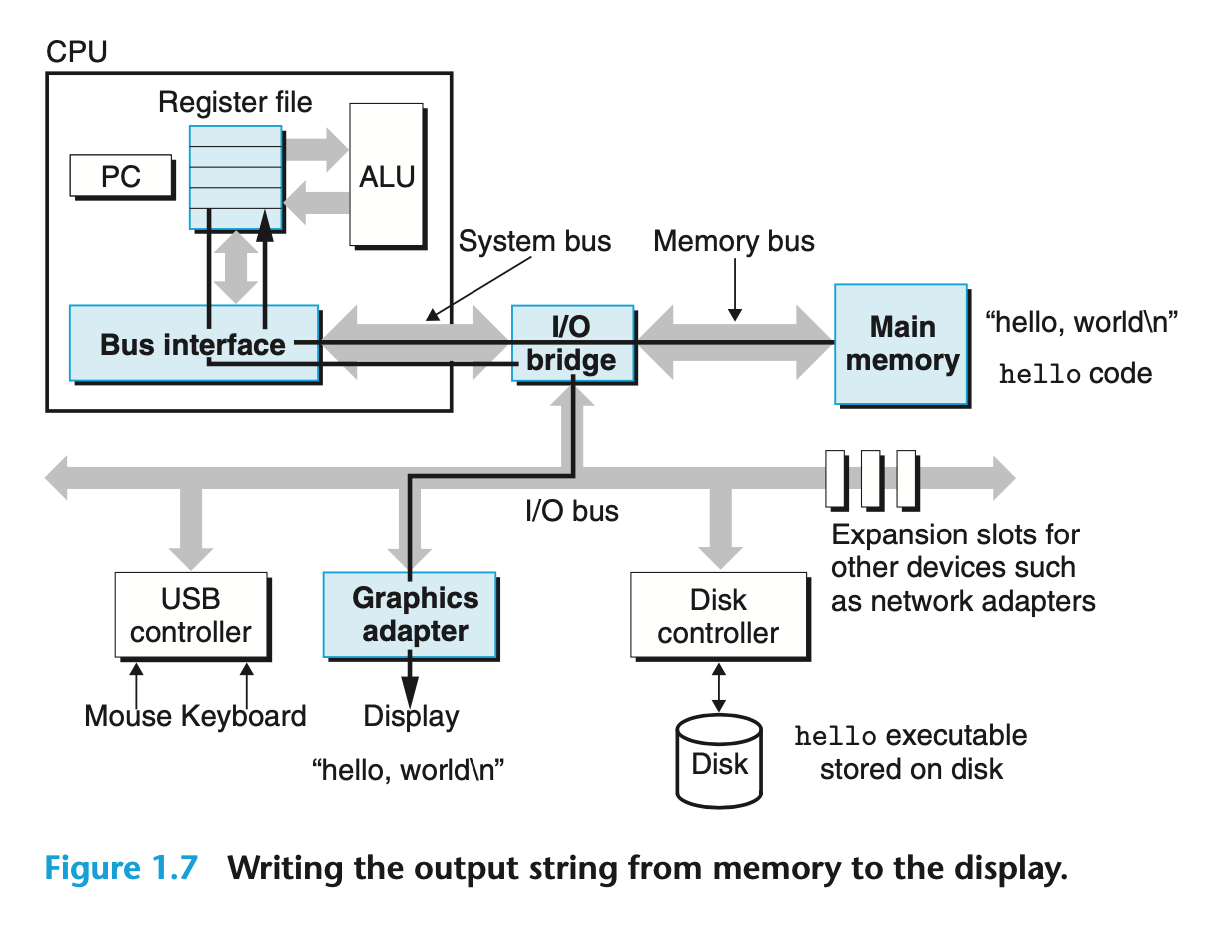
excutable hello 의 코드와 데이터가 memory에 로드되면 processor는 hello 프로그램의 main routine7에서 machine-language instruction들을 실행하기 시작한다.
이 instruction들은 hello, world\n 문자열의 byte를 register file로 복사하고, 거기에서 화면에 표시되는 디스플레이 장치로 복사한다.
위의 [Fig 1.7]을 참고하면 다음과 같다.
-> Main memory
-> I/O bridge
-> Bus interface
-> Register file
-> Bus interface
-> I/O bridge
-> Graphics adapter
와 같은 경로로, hello코드가 데이터를 표시하게 된다.
Summary
executable hello(코드 + 데이터)가 실행되는 루틴을 다시 한번 간단하게 살펴보면, 다음과 같다.
-> shell에 ./hello 를 입력
-> “hello”문자열을 keyboard, USB controller, I/O bridge의 System bus 통해 cpu로 전달
-> cpu에서 각 문자를 register로 읽은 후, 다시 I/O bridge를 통해 memory에 저장
-> shell에서 enter를 누른 순간, shell 은 “hello” executable object file의 코드와 데이터를 disk에서 main memory로 복사하는 일련의 instructions를 실행한다.
-> prcessor는 hello 프로그램의 main routine에서 machine-language instruction들을 실행한다.
-> instruction들은 hello, world\n 문자열을 register file로 복사하고, 거기에서 디스플레이 장치로 복사한다.
1.5 Caches Matter
위의 예에서 깨달은 점은, 시스템이 한 곳에서 다른 곳으로 정보를 이동하는데 많은 시간을 소비한다는 점이다.
hello program의 machine instruction과 data string의 이동경로는 다음과 같다.
machine instruction : disk ->(program load by shell)-> main memory ->(program execute)-> processor
data string : disk ->(program load by shell)-> main memory ->(program execute)-> display device
위와 같은 복사의 대부분은 실제 작업을 느리게 하는 오버헤드이다. 따라서, 시스템 설계자의 주요 목표는 이러한 복사 작업을 가능한 한 빨리 실행하는 것이다.
물리적인 이유로, 큰 용량의 디바이스는 작은 용량의 디바이스보다 느리다. 그리고 빠른 디바이스는 느린 디바이스보다 비싸다.
disk drive가 main memory 보다 1000배 크지만, disk에서 읽어오는 속도는 무려 10,000,000배 느리다.
비슷하게, 일반적인 레지스터 파일이 몇백 바이트의 정보를 저장하고 메인 메모리는 수십억 바이트의 정보를 저장하지만 레지스터 파일이 읽어오는 속도가 100배 빠르다.
그리고 반도체 기술이 수년에 걸쳐 발전함에 따라 processor-memory gap이 점점 커지고 있다.
왜냐하면, 프로세스를 빠르게 하는 것이 메인 메모리를 빠르게 하는 것보다 쉽고 저렴하기 때문이다.
processor-memory gap을 해소하기 위해 시스템 디자이너들은 더 작고 빠른 저장 디바이스인 cache memories(caches)를 사용한다. 이는 프로세스가 가까운 미래에 필요로 하는 정보를 임시로 저장하는 기능을 제공한다.
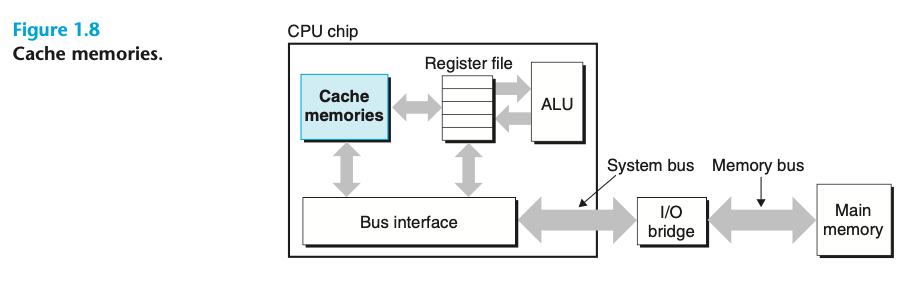
processor 안에 있는 L1 cache는 수만 byte를 저장하고 register file만큼 빠르게 접근할 수 있다.
L2 cache는 수십만 ~ 수백만 byte를 저장하고 special bus를 이용하여 프로세서와 연결되어 있다. 이것은 L1 cache보다 5배 느리지만, main memory보다는 여전히 5~10배 정도 빠르다.
L1, L2 cache는 모두 static random access memory로 이루어져 있다.
최근의 강력한 시스템은 3개의 level(L1, L2, L3)를 사용한다.
cache를 사용하는 이유
locality를 이용하여 매우 큰 메모리와 매우 빠른 캐시의 효과를 시스템이 얻을 수 있기 때문이다.
프로그램은 데이터와 코드를 지역화된 곳에 엑세스 하는 경향이 있다. 자주 액세스할 수 있는 데이터를 저장하도록 캐시를 설정함으로써 빠른 캐시를 사용하여 대부분의 메모리 작업을 수행할 수 있다.
-
0과 1로 이루어진 이진파일. exe파일이 그 예시. 기계어로 변환되어 실행할 준비를 마친 프로그램을 의미한다. ↩
-
여러부분으로 나누어져 있는 코드들을 하나로 합친다고 생각하면 될 것 같다. preprocessor는 파일 포함하는 부분 뿐만 아니라, if, else 같은 조건부 컴파일, 매크로 등등을 처리한다. ↩
-
스택 공간을 확보하고, 레지스터에 저장하고,, 등등 이런 명령어들을 표현한 것이다. ↩
-
hello.s는 machine language의 명령을 텍스트로 표현한 것이기 때문에, 이를 실제 명령으로 변환시키고 relocatable object program으로 패키징하는 것이다. ↩
-
컴퓨터 공학에서 컴퓨터의 CPU 또는 이와 관련된 디지털 신호 처리기의 전자 회로에 대한 설명(CPU 아키텍쳐라고도 함) ↩
-
흔히 말하는 main 함수 ↩